Technology
Introduction
Known means & systems of data modification – in electronic document format – can be divided into two major types:
-string editors/processors;
-computer languages integrated in string processors;
The main disadvantage of string editors/processors is low automation of string processing. Practically, if user needs to divide a big document into parts or change the format of some of its parts, then user has to do it manually. For instance: document has a certain number of sentences; to change appearance of each of them, user has to make a sequence of operations for each of document elements. The time spent on changes is proportional to amount of data in the document.
Computer languages integrated in string editors allow to solve data processing automation issue to some extent, but they also have some significant drawbacks making them no good for mass use; here are the major ones:
- complexity & labor intensity of writing data modification control commands;
- focus on fixed logical contents of document; set of commands can be applied only to document with internal structure known beforehand;
- tightly sticking to certain document format not allowing to apply code available to documents in formats different from the basic one.
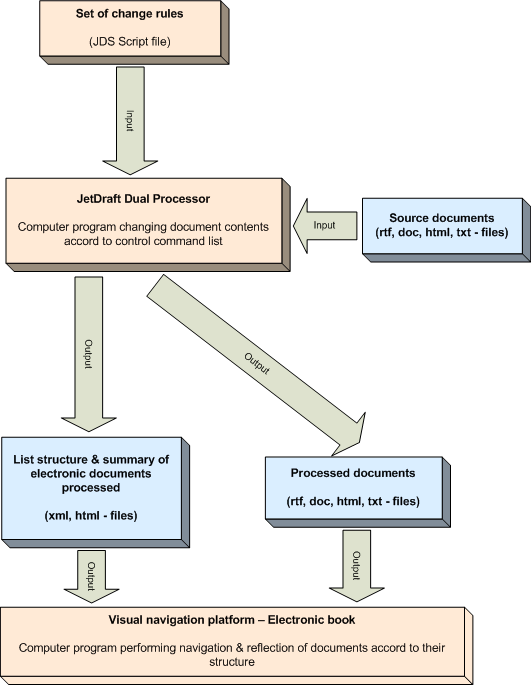
Document Suite provides means for document processing allowing user to operate document visual blocks through significantly simplified computer language without sticking to document contents or format. This approach allows to avoid repeating the same type operations to change data in documents of big volume.
Technical result obtained is increase in user labor productivity when s/he makes the same type operations to change data in electronic documents.
The essence of the approach to the problem of automation is to use logical rules control the content of the document. Here and further under the rule refers to the recording telling the system that need to perform certain actions on the electronic document or a part of it. The rules are universal and have no links to the format or to the internal structure of the document. The structure consists of the following rules parts: control functions, the body of data, the logical pointer for the withdrawal, the resulting object.
Schematically, this can be presented as the following writing:
CONTROL FUNCTION “data body” POINTER “resulting object”
Management function determines the basic rules of the appointment.
The body of data can include: Index boxes / truth pointer to the text, an object created by another rule, the method of processing data with a set of parameters, logical condition factions.
Index for the withdrawal is used for visual separation rules. Depending on the direction of the withdrawal of different indexes.
Main logical functions used in the system:
OPEN - data load from an outside source. Dependent on file, the function converts file to core format first, and then loads it to memory, decomposes it to internal format for further processing. It also allows to open a file set in one call for their package processing. Any undefined file opens as string file.
SAVE - data writing to external format
GROUP - New object creation function. It writes the result into the new project. Its operation result will be written into outcoming object for any method.
SHOW - data output to main system console
PRINT - data output to printer
RUN - external attachment launch
Logical conditions:
AS - ruler separator
FOR - logical “from and to”. It groups string object contents into big blocks. For instance, there is a “String data line” attachment; if you take the first and the last symbols of the sentence and apply condition “first symbol” FROM AND TO “last symbol”, then you get a sentence pointer.
AND - it includes an element into new object only if it occurs in both key objects.
OUT – it processes lists & includes only those elements into new object that do not match.
OR - it makes one list out of two.
Logically, the system perceives any string document as a collection of separate blocks.
As a summary, data analysis goes as follows:
- the system reads the document:
- perceives separate symbols;
- combines symbols into words using gaps as logical separators;
- full stops, switches to new, tabulation shifts-in, are perceived as sentence separators;
- paragraphs get combined into chapters;
- chapters get combined into sections;
Data is presented as a logical unit of block at each of these stages.
Data processing using suggested method can be divided to the following stages:
- command analysis process start;
- build-up of list of documents subject to processing;
- documents decomposition to system data internal format;
- document segmentation to logical blocks;
- logical blocks modification;
- block contents summary;
- logical blocks composition from internal format to external publicly-accessible data storage format;
System operation general scheme